

データベースはクエリを効率よく実行するために最適な方法を自動で選びます。その「選ばれた方法」を確認できるのが SQLの実行計画 です。
実行計画を活用する事でSQLのパフォーマンスを改善する事が可能となります。
本ブログでは以下の環境を使用します。実際に試される方は下記のブログを参照ください。
PostgreSQL(Ver 16.4) :PostgreSQLのインストール
A5M2(A5:SQL Mk-2)(Ver 2.19.2):A5M2(A5:SQL Mk-2)のインストール(Zip版)
外部データベース接続方法:【PostgreSQL】「pgAdmin4」外部データベースサーバーの接続方法
【A5M2(A5:SQL Mk-2)】『SQLの実行計画』を学んでパフォーマンスを改善しよう!
A5M2(A5:SQL Mk-2) SQL実行計画とは?
SQL実行計画は、データベースがクエリを実行する際の「処理手順」を表したものです。たとえば以下のような情報を確認できます。
- スキャン方法:テーブル全体を読むか、インデックスを使うか
- 結合方法:テーブル同士を結合する方法
- コスト情報:クエリ実行に必要なリソース量の予測
A5M2(A5:SQL Mk-2)で実行計画を確認する方法
実行計画を確認するには、以下の2つのコマンドを使います:
- EXPLAIN:実行計画を表示(実際にはデータを取得しない)
- EXPLAIN ANALYZE:実際にクエリを実行し、詳細な実行計画を表示。
A5M2(A5:SQL Mk-2)で実際に「実行計画」を見てみる
テーブルの準備
次のようなテーブルを作成します。
create table public.bookstock (
book_id serial not null
, title character varying(150) not null
, author character varying(100)
, price numeric(10, 2) not null
, stock integer default 0
, created_at timestamp(6) without time zone default now()
, primary key (book_id)
);
作成したテーブルにダミーデータを10,000件追加します。
実行するSQLクエリ
ここでbookstockテーブルのデータをstock数の多い順に並べてみましょう。SQLは以下となります。このクエリがデータベース内でどの様に実行されるのかを見てみます。
SELECT * FROM bookstock ORDER BYDESCstock;
EXPLAIN 指定時
EXPLAIN SELECT * FROM bookstock ORDER BY stock DESC;実行計画は以下のように表示されます。
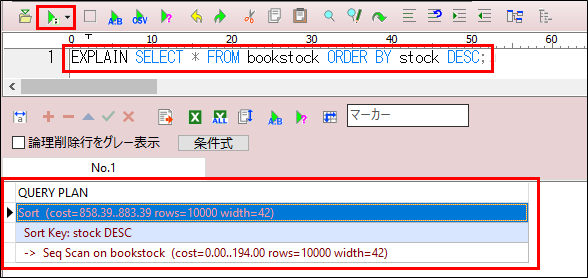
Sort (cost=858.39..883.39 rows=10000 width=42)Sort Key: stock DESC
-> Seq Scan on bookstock (cost=0.00..194.00 rows=10000 width=42)
解説
- Sort ノード
- 並び替えの基準は stock 列の降順
- cost=858.39..883.39 rows=10000 width=42
- 起点コスト (858.39):ソート処理を開始するために必要なリソース量(CPUやI/O)
- 終点コスト (883.39):ソート処理が完了するまでの推定コスト
- ソート処理のコストが高いのは、stock 列にインデックスがないため、全てのデータを並び替える必要があるからです。
- 行数 (rows)
- 推定されるソート対象の行数は10,000行
- 行幅 (width)
- 1行あたりの平均サイズは42バイトと推定
- Seq Scanノード
- 順次スキャン
- cost=0.00..194.00 rows=10000 width=42
- コスト
- 起点コスト (0.00)
テーブルスキャンを開始する際のコスト(主にディスクアクセスの初期コスト) - 終点コスト (194.00)
全行をスキャンし終えるまでの推定コスト- スキャンのコストが比較的低いのは、データが連続して格納されているため効率的に読み取れることを意味しています。
- 起点コスト (0.00)
全体のコスト評価
- 全体コスト
- Seq Scanの終了コスト (194.00) + Sortの終了コスト (883.39) = 1,077.39
これは、データを取得して並び替えるまでに必要なリソース量の合計です。
- Seq Scanの終了コスト (194.00) + Sortの終了コスト (883.39) = 1,077.39
- なぜコストが高いのか
- テーブルにインデックスがないため、全行をスキャンした後で全データをメモリにロードして並び替えを行う必要があるからです。
EXPLAIN ANALYZE 指定時
EXPLAIN ANALYZE SELECT * FROM books ORDER BY stock DESC;実行結果は以下のように表示されます。
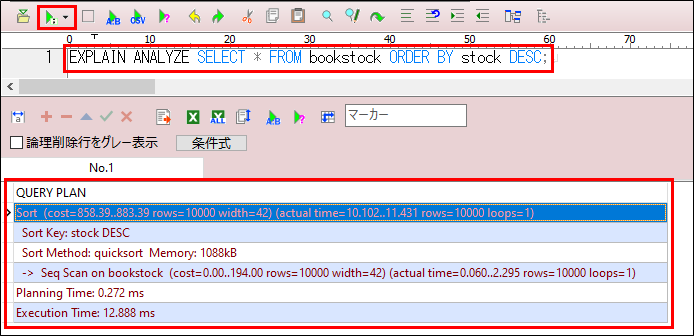
Sort (cost=858.39..883.39 rows=10000 width=42) (actual time=10.102..11.431 rows=10000 loops=1) Sort Key: stock DESC
Sort Method: quicksort Memory: 1088kB -> Seq Scan on bookstock (cost=0.00..194.00 rows=10000 width=42) (actual time=0.060..2.295 rows=10000 loops=1)
Planning Time: 0.272 ms
Execution Time: 12.888 ms解説
- Sort ノード
- costはEXPLAIN指定時と同様
- actual time=10.102..11.431 rows=10000 loops=1
並べ替え操作に実際にかかった時間をミリ秒単位で示しています(約1.33ms)。
- Sort Method:quicksort
- ソート方式はクイックソートアルゴリズムを使用
- Memory:1,088kB
- クイックソートのために使用されたメモリ量(1MB強)
- Seq Scanノード
- 順次スキャン
- cost=0.00..194.00 rows=10000 width=42
- コスト
EXPLAIN指定時と同様 - actual time=0.064..2.260
スキャンに実際にかかった時間 約2.2ms
- Planning Time:0.272 ms
クエリを実行する計画(実行計画の生成)にかかった時間(約0.27ms) - Execution Time:12.888 ms
実際のクエリ実行全体にかかった時間(約12.9ms)
考察と最適化ポイント
- 並べ替え(Sort)のコスト
- 並べ替え操作自体はquicksortを使用して効率的に実行されていますが、データ量が増えるとメモリ使用量や実行時間が大きくなる可能性があります。
- 頻繁にstock列を降順でソートするクエリを実行する場合、インデックスを作成することでパフォーマンスを改善できます。
インデックスを作成して試してみる
下記のように「stock」列にインデックスを作成してEXPLAIN ANALYZEで試してみます。
CREATE INDEX idx_stock ON bookstock(stock);結果は以下の通り。
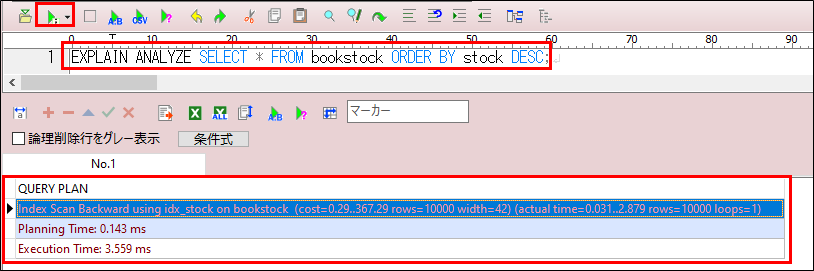
- Planning Time: 0.143 ms
- クエリを実行する計画にかかった時間 約-0.13ms短縮
- Execution Time: 3.559 ms
- 実際のクエリ実行全体にかかった時間 約-9.3ms短縮
インデックスを設定する事で処理時間を短縮する事ができた。
A5M2(A5:SQL Mk-2)で実行計画を活用するポイント
- クエリの改善箇所を特定
- 不必要なシーケンシャルスキャンや、結合方法の改善を確認します。
- インデックスの効果を検証
- インデックスを追加した後のコストの変化を比較できます。
- 複雑なクエリを分析
- 複数のテーブルを結合したクエリでも、どの処理に時間がかかっているかが分かります。
なぜ実行計画を確認するのか?
実行計画を確認することで以下が可能になります。
- ボトルネックの特定
- 不要なスキャンの発見
- インデックスが効果的に利用されているかの確認
まとめ:A5M2(A5:SQL Mk-2)実行計画活用でパフォーマンス向上
A5:SQL Mk-2のSQL実行計画ツールを活用することで、SQLクエリを最適化でき実行のパフォーマンスを大幅に向上させることができます。
実行計画を確認するには、以下の2つのコマンドを使います。
- EXPLAIN
実行計画を表示(実際にはデータを取得しない) - EXPLAIN ANALYZE
実際にクエリを実行し、詳細な実行計画を表示

