

PostgreSQLで全文検索を使う理由
Webアプリや業務システムで「検索機能」は欠かせません。PostgreSQLは、標準SQLだけでなく強力な全文検索機能を備えており、特にpg_trgm拡張を使うことで、LIKE検索より高速かつ柔軟な検索が可能になります。
使用環境
- Windows 11 Pro 24H2
- PostgreSQL 17.6
- pgAdmin4 9.6
- Chrome 134.0.6998.205
LIKE検索とpg_trgmの違い
LIKE検索
- SQL標準の部分一致検索にしか過ぎない
- 例:WHERE content LIKE ‘%検索%’
%は任意の文字列を表すワイルドカード
- 問題点
- インデックスが効きにくい(特に先頭に
%がある場合) - 大量データになると検索が遅くなる
- インデックスが効きにくい(特に先頭に
pg_trgm
- 全文検索をする為の拡張機能
- 文字列を「3文字ずつの断片(トライグラム)」に分解して類似度を計算
- 例:
WHERE content % '検索'(%はpg_trgm演算子)
- 利点
- 類似検索が可能(完全一致でなくてもヒット)
- インデックス(GINインデックス)と組み合わせると高速
GINインデックス
LIKE検索・pg_trgm どちらを使用すべきか?
- 小規模・簡易検索
- LIKEで十分
- 大量データ・類似検索・高速化
- pg_trgm+GINインデックスが圧倒的に有利
LIKE検索・pg_trgm 比較準備
サンプルテーブルの作成とデータ登録
- 下記サンプルプログラムを作成します。サンプルプログラムの目的は、
- LIKE検索とpg_trgm検索の違いを体感する
- GINインデックスの有無による速度差を確認する
- 類似語や誤字でもヒットするかを試す(下記プログラムの、WHEN i % 3 = 1 THEN ‘PosgrelSQLは高速な検索が可能です。’ では、PostgreSQL を PosgrelSQL にしています。)
-- サンプルプログラム
CREATE TABLE articles (
id SERIAL PRIMARY KEY,
title TEXT,
content TEXT
);
-- 10000件のサンプルデータを生成(実験用)
INSERT INTO articles (title, content)
SELECT
'記事' || i,
CASE
WHEN i % 3 = 0 THEN 'PostgreSQLの全文検索は便利です。'
WHEN i % 3 = 1 THEN 'PosgrelSQLは高速な検索が可能です。'
ELSE 'PostgreSQLはオープンソースのRDBMSです。'
END
FROM generate_series(1, 10000) AS s(i);SQLでの拡張機能「pg_trgm」の有効化
- psql で以下のSQLを実行
CREATE EXTENSION IF NOT EXISTS pg_trgm;LIKE検索・pg_trgm検索結果の比較
pgAdmin4 による検索結果の比較
ここでは、初心者向けでもある為、pgAdmin4の「クエリツール」で確認します。
pgAdmin4 のクエリ完了時間 とは
pgAdmin 4がクエリをPostgreSQLに送信し、サーバーが処理して結果を返し、pgAdminがそれを受け取って表示するまでの一連の流れにかかった時間です。(以下の表の合計時間)
| 処理ステップ | 内 容 |
|---|---|
| クエリ送信 | pgAdmin → PostgreSQLサーバーへSQLを送信 |
| 実行計画構築 | PostgreSQLが最適な実行方法を決定(Planning Time) |
| 実行処理 | 実際にデータを読み込んで処理(Execution Time |
| 結果返却 | PostgreSQL → pgAdminへ結果を返す |
| 表示処理 | 表示処理 |
サーバー側の実行処理のみの時間や、実行前の準備の時間を知りたい場合
以下のコマンドを使用します。
- LIKE検索
EXPLAIN ANALYZE SELECT * FROM articles WHERE content LIKE '%PostgreSQL%';- pg_trgm検索
EXPLAIN ANALYZE SELECT * FROM articles WHERE content % 'PostgreSQL';pgAdmin4 による検索結果
- LIKEの実行確認用SQL
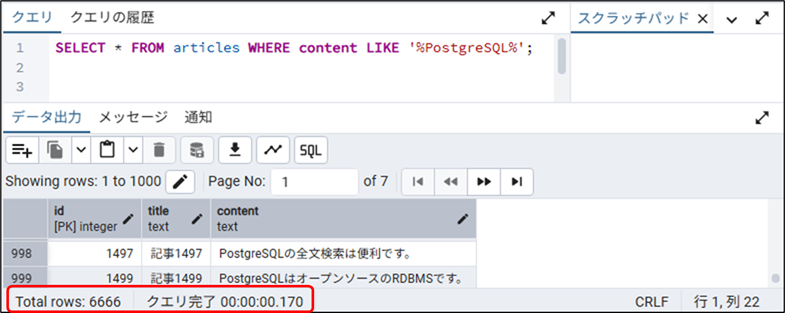
-- 部分一致検索(検索語:PostgreSQL)
SELECT * FROM articles WHERE content LIKE '%PostgreSQL%';- 実行結果と実行時間
- 検索件数:6,666件
- 検索時間:0.170ms
- pg_trgmの実行確認用SQL
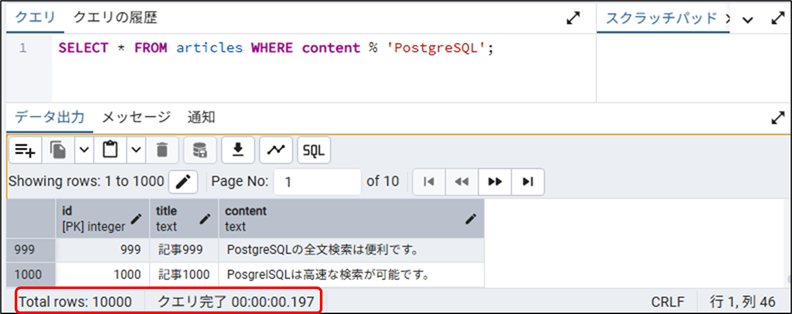
-- pg_trgm検索(類似度)
SELECT * FROM articles WHERE content % 'PostgreSQL';- 実行結果と実行時間
- 検索件数:10,000件
- 検索時間:0.197ms
- 類似文字(ここでは、PosgrelSQL)も検索されている為多少時間がかかっていると思われる。
インデックスの作成とパフォーマンス比較
GINインデックス作成
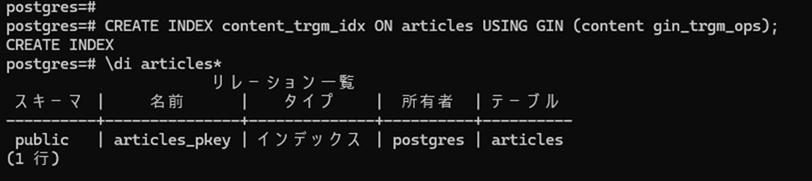
- 下記のSQLを実行してGINインデックス作成を作成します
CREATE INDEX articles_idx ON articles USING GIN (content gin_trgm_ops);- インデックスが作成されているか?
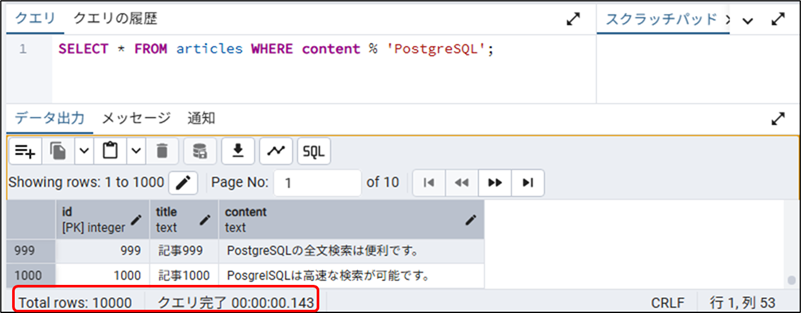
- pg_trgm+GINインデックスの実行結果
PostgreSQL 「フルテキスト検索入門」 まとめ
PostgreSQLでの文字列検索は、LIKE '%文字列%' が基本ですが、インデックスが効かず遅くなりがちです。そこで登場するのが pg_trgm 拡張。曖昧検索を高速化する強力な武器です。
- LIKE検索の課題
%で始まる検索はインデックスが使えない- 全件走査(Seq Scan)になり、件数が多いと遅い
- 日本語や長文では特に非効率
- pg_trgmとは?
- 「トライグラム(3文字単位)」で文字列を分割し、類似度を計算
%演算子で曖昧検索が可能(content % '検索語')- GINインデックスと組み合わせることで爆速化

