

はじめに
本ブログでは、初心者〜中級者向けにPostgreSQLのレプリケーション構築手順を紹介します。レプリケーションは大きく分けると、
- データベースクラスタを一括して複製する「ストリーミングレプリケーション(物理レプリケーション)」
- テーブル単位やデータベース単位に複製する「ロジカルレプリケーション(論理レプリケーション)」
があります。ここでは「ストリーミングレプリケーション」の構築を中心に紹介します。
PostgreSQLレプリケーションとは? なぜ必要?
レプリケーションとは、1つのデータベース(プライマリ)から別のデータベース(スタンバイ)へリアルタイムでデータを複製する仕組みです。
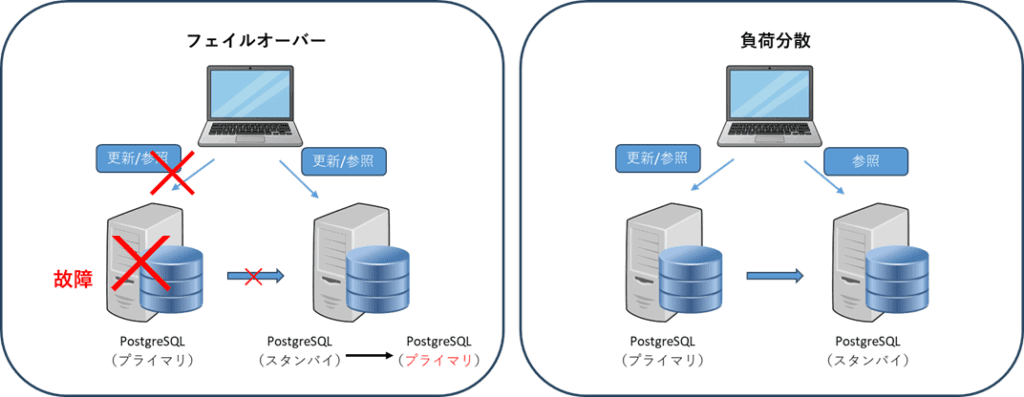
複製を作成するメリットは、
- 障害時の迅速な復旧(フェイルオーバー)
プライマリが故障した場合、複製のスタンバイを使用する - 読み取り負荷の分散(参照系クエリの負荷分散)
ユーザーからの多くのクエリ(参照系)スタンバイに分散させる事で、全体として処理能力を高める - 災害対策(DR)
スタンバイを遠くの地域に置く事で、災害からのデータ損失のリスクを減少させる
等です。
レプリケーションのアーキテクチャ
ストリーミングでもロジカルでも、基本的な仕組みは「WAL」を使用している事です。
「WAL」(Write Ahead Log)とは、データベースへの変更内容が全て記録されているログの事で、この「WAL」を別のPostgreSQLに転送・リカバリして複製を作成し、レプリケーションを実現しています。
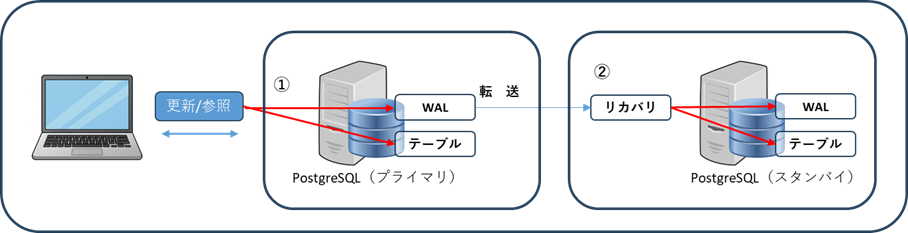
- ①クエリにより「WAL」が生成され、テーブルが更新される。
- ②スタンバイに転送されてきた「WAL」をそのまま「WAL」ファイルに書き込み、「WAL」の内容で、テーブルを更新する。
※プライマリから送られてきた「WAL」をそのまま適用する為、以下の条件が必要となります。
- PostgreSQLのメジャーバージョンが同じであること
- マスタとスタンバイは同じWALフォーマット・バージョンである必要あり
- ハードウェアやOSのアーキテクチャが同じである事
ストリーミングレプリケーションの特徴
ストリーミングレプリケーションは、WAL(Write-Ahead Logging)ファイルをリアルタイムでスタンバイサーバに転送することで、プライマリとスタンバイ間のデータ同期を実現します。
- 特徴
- プライマリで生成されたWALファイルを、TCP接続を通じてスタンバイに送信
- ファイルコピーではなく、ストリーム転送なので即時性が高い
- スタンバイ側はSELECTのみ可能(書き込み不可)
使用環境
- Windows 11 Pro 24H2
- PostgreSQL 17.6
- プライマリサーバのIP :192.168.0.80
- スタンバイサーバーのIP:192.168.0.60
ストリーミングレプリケーションの設定
プライマリサーバの設定
postgresql.confの設定
postgresql.confはメイン設定ファイルであり、データベースの動作に関するさまざまなパラメータを定義する重要な役割を担っています
先ずは、postgresql.confをプライマリサーバ用に設定します。
- 基本接続
listen_addresses = '*' #外部からの全ての接続を許可
port = 5432 #デフォルトの待ち受けポート- WAL(Write-Ahead Logging)関連設定
wal_level = replica #レプリケーション用にreplicaを指定
#ロジカルなら logical を指定
max_wal_senders = 5 #スタンバイ接続数の上限(必要に応じて設定)
wal_keep_size = '256MB' #WALファイルの保持サイズ。遅延対策に有効。- 同期レプリケーション設定
synchronous_commit = on #同期レプリケーションを明示的に指定
#標準は、on
synchronous_standby_names = 'standby01' #同期レプリケーションを使用する場合の
#スタンバイ側の名称を指定- ログ出力設定(トラブルシューティング)
logging_collector = on
log_directory = 'log'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_connections = on
log_disconnections = on- メモリ・パフォーマンス関連(環境に応じて調整)
shared_buffers = '512MB' #PostgreSQLが使用するメモリ領域。物理メモリの
#25〜40%が目安。
effective_cache_size = '1GB' #OS側のキャッシュ見積もり。クエリプランに影響。
work_mem = '4MB' #ソートやハッシュ処理に使うメモリ。
#複雑なクエリが多い場合は増やす。
maintenance_work_mem = '64MB' #PostgreSQLが「メンテナンス系の処理」を
#行うときに使うメモリの上限上記の値は必要に応じて設定してください。
pg_hba.confファイルの設定
pg_hba.confは接続認証の制御ファイルで、誰が・どこから・どの方法で接続できるかを定義します。
インストールされたファイルはUNIX用なので、以下の様にWndows用に書き換えます。
# TYPE DATABASE USER ADDRESS METHOD
# IPv4 local connections:
host all all 127.0.0.1/32 scram-sha-256
# IPv6 local connections:
host all all ::1/128 scram-sha-256
# Allow replication connections from localhost, by a user with the replication privilege.
host replication replicator 192.168.0.60/24 scram-sha-256- host all all 127.0.0.1/24 scram-sha-256
すべてのデータベースに対して、全てのユーザーから接続を許可しています。 - host replication replicator 192.168.0.60/24 scram-sha-256
レプリケーション専用接続で、ID:replicatorで(192.168.0.1~254:スタンバイサーバー)からプライマリサーバ(192.168.0.80)にアクセスを許可しています。
レプリケーション権限を持つユーザーの作成
- 下記コマンドで作成します。
CREATE ROLE replicator WITH REPLICATION LOGIN PASSWORD 'reppass';PostgreSQLサービス再起動(PowerShell)
- PostgreSQLが正常に再起動するか確認します。
Restart-Service -Name postgresql-x64-17スタンバイサーバーの設定
初期同期の実行
pg_basebackupでプライマリからデータを取得し、初期同期を実行します。
- C:\pgsql フォルダを作成
mkdir C:\pgsql- 下記コマンドで初期同期を実行
cd "C:\Program Files\PostgreSQL\17\bin"
.\pg_basebackup.exe -h 192.168.0.80 -D "C:\pgsql\standby_data" -U replicator -P -R -Wこれから以後のファイル設定は、”C:\pgsql\standby_data” 内のファイルに対して行います。
postgresql.auto.conf の内容追加
postgresql.auto.conf に下記の内容を追加します。application_name はプライマリ側の synchronous_standby_names に一致させると同期レプリケーションが可能となります。
primary_conninfo = 'host=192.168.0.80 port=5432 user=replicator password=reppass application_name=standby01'standby.signal ファイルの作成(自動作成されていない場合)
内容は無くてもよいが、このファイルが存在することで、PostgreSQLはスタンバイモードで起動します。作成方法は下記コマンドを実行。
New-Item -Path "C:\pgsql\standby_data\standby.signal" -ItemType Filepostgresql.conf の調整
postgresql.conf ファイルの内容が、下記のようになるよう調整します。
# 接続関連
listen_addresses = '*' # 外部からの接続を許可
port = 5432 # 通常のPostgreSQLポート
# WAL受信と適用
wal_level = replica # WALを受信する最低レベル
hot_standby = on # スタンバイでもSELECTなどの読み取りを許可
wal_receiver_status_interval = 1s # プライマリへの受信状況報告間隔
wal_retrieve_retry_interval = 3s # WAL取得失敗時の再試行間隔
# ログ出力(トラブル時の診断に必須)
logging_collector = on
log_directory = 'log'
log_filename = 'postgresql-%Y-%m-%d_%H%M%S.log'
log_min_messages = info
log_connections = on
log_disconnections = onhot_standby = on により、スタンバイでも読み取りクエリが可能になります。
サービスの登録と起動(初回のみ)
- サービスの登録
スタンバイ側で下記のコマンドを実行して「pgsql-standby」サービスを登録します。 C:\Program Files\PostgreSQL\17\bin にパスを通すか、ディレクトリに移動して実行。
cd "C:\Program Files\PostgreSQL\17\bin"
./pg_ctl register -N "pgsql-standby" -D "C:\pgsql\standby_data"- サービスの起動
下記コマンドを実行
Start-Service -Name pgsql-standby- 動作確認
下記SELECT文で、trueが返ればスタンバイとして動作中です。
SELECT pg_is_in_recovery();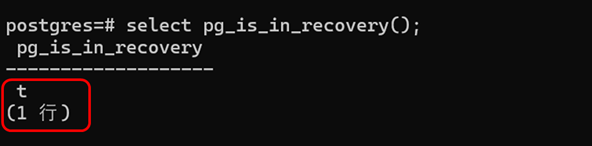
レプリケーション動作の確認
プライマリ側のテーブルに1件のレコードを追加した場合、スタンバイ側にも同様に追加されるか確認してみます。
- プライマリ側の操作
articlesテーブルに1件のレコードを追加
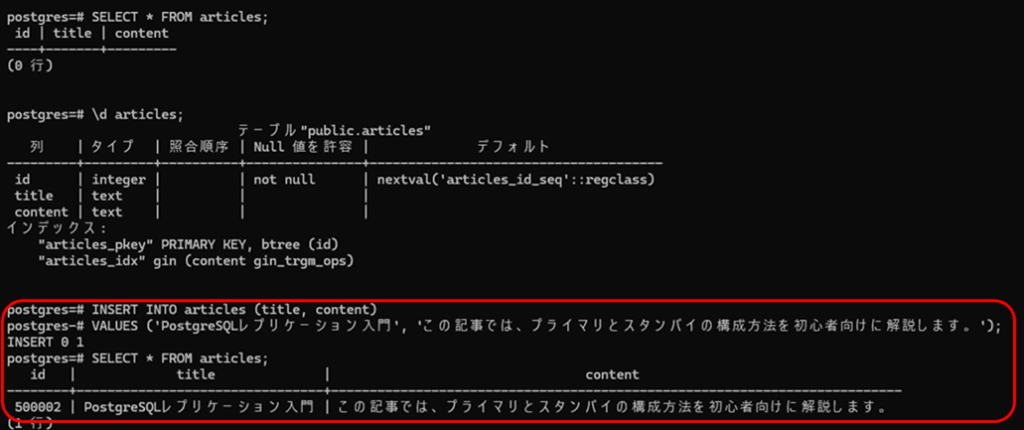
- スタンドバイ側の状態
プライマリ側に追加されたレコードが、スタンドバイ側にも追加され、同期している事が確認できます。

ストリーミングレプリケーションのまとめ
ストリーミングレプリケーションは、基本的にデータベース全体を複製します。レプリケーションの元となるサーバーは1台だけ設定できますが、スタンバイは複数台設定できます。又、スタンバイサーバーで実行できるのは参照系のクエリのみです。
冒頭でも述べましたが、ストリーミングレプリケーションは、PostgreSQLの高可用性を実現する重要な機能です。設定はシンプルですが、細部の確認が成功の鍵。この記事を参考に、安全で再現性の高い構成を作成して下さい。

